"In this exercise, we will be doing image classification with a simple neural network. For simplicity, let's assume we will be working with black and white images.\n",
"Given an input image $i$ represented as a vector of pixel intensities $ \\mathbf{x}_i \\in [0,1]^d$, we want to predict its correct label $\\mathbf{y}_i$, which is represented as a one-hot vector in $\\{0,1\\}^K$, where $K$ is the number of possible categories (classes) that the image may belong to. For example, we may have pictures of cats and dogs, and our goal would be to correctly tag those images as either cat or dog. In that case we would have $K=2$, and the vectors $\\begin{pmatrix}0 \\\\ 1\\end{pmatrix}$ and $\\begin{pmatrix}1 \\\\ 0\\end{pmatrix}$ to represent the classes of cat and dog. \n",
"\n",
"In today's example we will be using the MNIST handwritten digit dataset. It contains images of handwritten numbers from 0 to 9 and our goal is to create a model that can accurately tag each image with its number. Let's load the data first."
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "exact-cycling",
"metadata": {},
"outputs": [],
"source": [
"### Load the data\n",
"\n",
"# Download data if needed\n",
"if not Path(\"./mnist_data.npz\").is_file():\n",
" r = requests.get('https://os.unil.cloud.switch.ch/swift/v1/lts2-ee312/mnist_data.npz', allow_redirects=True)\n",
" with open('mnist_data.npz', 'wb') as f: # save locally\n",
" f.write(r.content)\n",
"\n",
"\n",
"mnist = np.load('mnist_data.npz')"
]
},
{
"cell_type": "markdown",
"id": "varying-taylor",
"metadata": {},
"source": [
"In the context of classification, neural networks are models that given one (or multiple) input data points produce as output a set of corresponding labels for each input. The model itself consists of parametric functions $g_i$ which can be applied sequentially to the input data, resulting in a set of labels which are the model's prediction for the data. For example, in a model that consists of two parameteric functions $g_1$ and $g_2$, for a given $\\mathbf{x}_i$, we have the predicted label $ \\hat{\\mathbf{y}}_i = g_1(g_2(\\mathbf{x}_i))$. The parametric functions are commonly called \"layers\".\n",
"\n",
"In a standard image classification setup, we are given some training data which we can use to tune the parameters of the parametric functions $g_i$ in order to improve its ability to predict the labels correctly. The parameters are generally tuned with respect to some objective (commonly called a loss function). We want to find the parameters of the model that minimize this loss function. Various loss functions can be used, but in general they tend to encode how \"wrong\" the model is. For\n",
"example, on a given image $i$ one can use the loss $\\mathcal{L}(\\hat{\\mathbf{y}_i}, \\mathbf{y}_i)= \\sum_{j=1}^{K}(\\hat{{y}}_{ij} -{y}_{ij})^2 $, which is the mean squared difference between the vector coordinates of the predicted label of the image and the ones of the actual label $\\mathbf{y}_i$.\n",
"Minimizing the loss over the whole training set is referred to as \"training the model\". Furthermore, the goal is that given new data we have not seen before and we have not trained our model with, the model will still be able to classify accurately.\n",
"\n",
"Before we go into the details of the model and how we will train it, let's prepare the data."
"For our task, we will be using Radial Basis Function (RBF) Networks as our neural network model.\n",
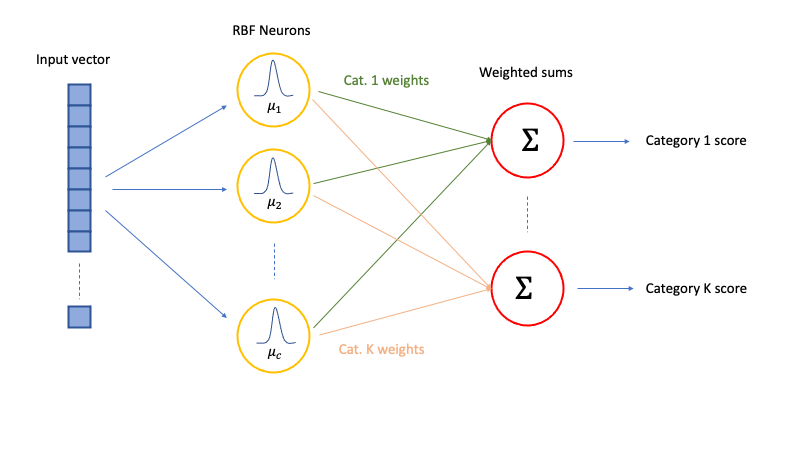
"The pipeline, which is presented in the image below, consists of two layers. The first employs non-linear functions $g_1(\\mathbf{x};\\boldsymbol{\\mu}): \\mathbb{R}^{n \\times d} \\rightarrow \\mathbb{R}^{n \\times c}$.\n",
"The second is a linear layer, represented by a matrix of weights $\\mathbf{W} \\in \\mathbb{R}^{c \\times K}$, which maps the output of the previous layer to class scores; its role is to predict labels. \n",
"\n",
"The pipeline proceeds in the following steps:\n",
"\n",
"i) Choose a set of $c$ points $\\boldsymbol{\\mu}_j\\in [0,1]^d$. \n",
"ii) Compute $g_1(\\mathbf{x}_i;\\boldsymbol{\\mu}_j) = \\exp^{-\\frac{||{\\mathbf{x}_i-\\boldsymbol{\\mu}_j||^2}}{\\sigma^2}}=a_{ij}$ for all possible pairs of $i$ and $j$. Here $\\sigma$ is a hyperparameter that controls the width of the gaussian. \n",
"iii) Compute the predicted labels $g_2(\\mathbf{a}_i)= \\mathbf{a}_i^{\\top}\\mathbf{W}= \\hat{\\mathbf{y}}_i$. Here $\\mathbf{a}_i \\in \\mathbb{R}^c$ are the outputs of the layer $g_1$ for an input image $i$. $\\hat{\\mathbf{y}}_i$ is a row vector and $\\hat{y}_{ij} = \\sum_{m=1}^{c}a_{im}w_{mj}$, $j\\in\\{1,...,K\\}$. \n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "f762f16e-4a88-43a8-813f-c93c62407c72",
"metadata": {},
"source": [
"Intuitively, the first layer of the RBF network can be viewed as matching the input data with a set of prototypes (templates) through a gaussian whose width is determined by $\\sigma$. The second layer performs a weighted combination of the matching scores of the previous layer to determine the predicted label for a given point. "
]
},
{
"cell_type": "markdown",
"id": "126fdb8e-9607-4f93-9726-692e5ed8bb91",
"metadata": {
"deletable": false,
"editable": false
},
"source": [
"**1.** For hyperparameters $c$ and $\\sigma$ of your choice, select $c$ prototypes and obtain the output of the first layer of the RBF network. The prototypes can simply be random images from your training set.\n",
"You can (optionally) perform an additional normalization step on the activations using the [softmax](https://docs.scipy.org/doc/scipy/reference/generated/scipy.special.softmax.html) function.\n"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "0e4ab127-352e-49c3-9b72-9e69bfc8b4ba",
"metadata": {
"tags": [
"otter_assign_solution_cell"
]
},
"outputs": [],
"source": [
"def get_rand_centers(num_centers, imgs):\n",
" \"\"\"\n",
" Sample num_centers (randomly) from imgs\n",
"\n",
" Parameters\n",
" ----------\n",
" num_centers : number of samples\n",
" imgs : matrix to sample rows from\n",
"\n",
" Returns\n",
" -------\n",
" The samples matrix\n",
" \"\"\"\n",
" # BEGIN SOLUTION\n",
" num_imgs = imgs.shape[0]\n",
" if num_centers > num_imgs or num_centers < 1:\n",
" raise ValueError(\"Invalid number of centers requested\")\n",
"To make things easier, we will fix the parameters $\\boldsymbol{\\mu}$ and $\\sigma$ of the network, i.e., we decide their values before and the remain constant throughout training and testing of the model. Therefore, the only trainable parameters are going to be the weights of the second layer.\n",
"To train the model, we are going to use the mean squared loss function that we mentioned earlier. For a training dataset with $n$ images we have\n",
"Backpropagation depends on [gradient descent](https://en.wikipedia.org/wiki/Gradient_descent#Description). The goal is to update the trainable parameters of the network by \"moving them\" in the direction that will decrease the loss function.\n",
"In our case, the weights $w_{kl}$ are updated in the following manner\n",
"where $\\gamma$ is a hyper-parameter called the learning rate. The gradient of the Loss points towards the direction of steepest descent, hence we update the weights of the network towards that direction. \n",
"\n",
"\n",
"---"
]
},
{
"cell_type": "markdown",
"id": "189e8b8e-a909-4f9e-950a-e0f65a48d70c",
"metadata": {
"deletable": false,
"editable": false
},
"source": [
"<!-- BEGIN QUESTION -->\n",
"\n",
"2. For the mean squared error loss, what is the gradient of the loss with respect to the weights $w_{kl}$ of the network?"
]
},
{
"cell_type": "markdown",
"id": "0df8dee2",
"metadata": {
"tags": [
"otter_answer_cell"
]
},
"source": [
"_Type your answer here, replacing this text._"
]
},
{
"cell_type": "markdown",
"id": "9813a207-46ae-4891-9b43-1b59a2a3717c",
"metadata": {
"tags": [
"otter_assign_solution_cell"
]
},
"source": [
"First let us expand the expression of the loss:\n",
"3. Train the weights of the linear layer using stochastic gradient descent. For $p$ iterations (called epochs), you have to update each weight $w_{kl}$ of the network once for each image, by computing the gradient of the loss with respect to that weight.\n",
"\n",
"NB: if you implement gradient computation naively, it might be very slow. Consider using [numpy.outer](https://numpy.org/doc/stable/reference/generated/numpy.outer.html) to speed up computation.\n"
"print(f\"The accuracy on the test set is: {get_accuracy(test_predictions, int_labels_test, test_set_size)*100} %\") "
]
},
{
"cell_type": "markdown",
"id": "promising-funds",
"metadata": {},
"source": [
"### 3.2 Solving the linear system"
]
},
{
"cell_type": "markdown",
"id": "f8234141-0eeb-49da-8d37-892a6416e41d",
"metadata": {},
"source": [
"Since we only have one weight matrix to tune, we can avoid learning with backpropagation entirely. Consider the mean squared error for the whole dataset and a one-dimensional binary label $y_i$ for each data point for simplicity. The mean squared loss for the dataset is\n",
"$$ \\sum_{i=1}^n (\\hat{{y}}_{i} - {y}_{i})^2= ||(\\mathbf{A}\\mathbf{w} - \\mathbf{y})||^2.$$ Here $\\mathbf{A} \\in \\mathbb{R}^{n \\times c}$ is the matrix that contains the outputs (activations) of the first layer. From a linear algebra perspective, we are looking for a matrix $\\mathbf{w}$ that solves the linear system $ \\mathbf{A}\\mathbf{w} = \\mathbf{y}.$ \n",
"\n",
"\n",
"---"
]
},
{
"cell_type": "markdown",
"id": "4e691348-afe4-4021-a42b-3985a4e9999e",
"metadata": {
"deletable": false,
"editable": false
},
"source": [
"<!-- BEGIN QUESTION -->\n",
"\n",
"4. Can we find solutions to this system (justify) and how ?"
]
},
{
"cell_type": "markdown",
"id": "cf9e153e",
"metadata": {
"tags": [
"otter_answer_cell"
]
},
"source": [
"_Type your answer here, replacing this text._"
]
},
{
"cell_type": "markdown",
"id": "express-office",
"metadata": {
"tags": [
"otter_assign_solution_cell"
]
},
"source": [
"The system is overdetermined. We have more equations (1 equation per data point) than unknown variables (1 variable for each template). We can find approximate solutions with a [least squares](https://en.wikipedia.org/wiki/Overdetermined_system#Approximate_solutions) approach, i.e., using the pseudoinverse."
]
},
{
"cell_type": "markdown",
"id": "subsequent-exercise",
"metadata": {
"deletable": false,
"editable": false
},
"source": [
"<!-- END QUESTION -->\n",
"\n",
"<!-- BEGIN QUESTION -->\n",
"\n",
"5. Based on your answer above, compute the weights of the neural network that best classify the data points of the training set."
"print(f\"The accuracy on the test set is: {get_accuracy(test_predictions_lsq, int_labels_test, test_set_size)*100} %\")"
]
},
{
"cell_type": "markdown",
"id": "handmade-warrant",
"metadata": {
"deletable": false,
"editable": false
},
"source": [
"<!-- END QUESTION -->\n",
"\n",
"<!-- BEGIN QUESTION -->\n",
"\n",
"### 6. **Open ended**: On the choice of templates. \n",
"Suggest a different or more refined way to select templates for the RBF network and implement it. Check how it compares with your original approach.\n",
"Check how it works with the backpropagation and linear system solutions."
]
},
{
"cell_type": "markdown",
"id": "4b05dc5e",
"metadata": {
"tags": [
"otter_answer_cell"
]
},
"source": [
"_Type your answer here, replacing this text._"
]
},
{
"cell_type": "markdown",
"id": "c84c3a52-26bd-49d5-b92c-724e6f309b82",
"metadata": {
"tags": [
"otter_assign_solution_cell"
]
},
"source": [
"Here are a few things that can be tried in order to better select the template images:\n",
"\n",
"- split up the images based on label and sample an equal amount of images from each class. This ensures that there won't be imbalances in the representations of templates/centers.\n",
"- split up the images based on label and furthermore subdivide the images of each class into a few groups. Compute the average image in each group. You will have a few \"average images\" in each class. Use those as centroids/templates. (All of this averaging stuff is easily done with matrix ops)\n",
"- filter the images (similar to how it was done in previous notebooks) and then sample extra centers from the filtered data. Use those as additional centers.\n",
"- apply standard clustering techniques like [K-Means](https://en.wikipedia.org/wiki/K-means_clustering) and [Spectral Clustering](https://en.wikipedia.org/wiki/Spectral_clustering)"
## Week 8 - Image classification with Radial Basis Function (RBF) networks
[LTS2](https://lts2.epfl.ch)
%% Cell type:code id:nasty-access tags:
``` python
importnumpyasnp
frommatplotlibimportpyplotasplt
fromsklearn.metricsimportpairwise_distances
fromscipy.spatialimportdistance_matrix
fromscipy.specialimportsoftmax
importrequests
frompathlibimportPath
```
%% Cell type:markdown id:vietnamese-basin tags:
## 1. Image Classification
In this exercise, we will be doing image classification with a simple neural network. For simplicity, let's assume we will be working with black and white images.
Given an input image $i$ represented as a vector of pixel intensities $ \mathbf{x}_i \in [0,1]^d$, we want to predict its correct label $\mathbf{y}_i$, which is represented as a one-hot vector in $\{0,1\}^K$, where $K$ is the number of possible categories (classes) that the image may belong to. For example, we may have pictures of cats and dogs, and our goal would be to correctly tag those images as either cat or dog. In that case we would have $K=2$, and the vectors $\begin{pmatrix}0 \\ 1\end{pmatrix}$ and $\begin{pmatrix}1 \\ 0\end{pmatrix}$ to represent the classes of cat and dog.
In today's example we will be using the MNIST handwritten digit dataset. It contains images of handwritten numbers from 0 to 9 and our goal is to create a model that can accurately tag each image with its number. Let's load the data first.
In the context of classification, neural networks are models that given one (or multiple) input data points produce as output a set of corresponding labels for each input. The model itself consists of parametric functions $g_i$ which can be applied sequentially to the input data, resulting in a set of labels which are the model's prediction for the data. For example, in a model that consists of two parameteric functions $g_1$ and $g_2$, for a given $\mathbf{x}_i$, we have the predicted label $ \hat{\mathbf{y}}_i = g_1(g_2(\mathbf{x}_i))$. The parametric functions are commonly called "layers".
In a standard image classification setup, we are given some training data which we can use to tune the parameters of the parametric functions $g_i$ in order to improve its ability to predict the labels correctly. The parameters are generally tuned with respect to some objective (commonly called a loss function). We want to find the parameters of the model that minimize this loss function. Various loss functions can be used, but in general they tend to encode how "wrong" the model is. For
example, on a given image $i$ one can use the loss $\mathcal{L}(\hat{\mathbf{y}_i}, \mathbf{y}_i)= \sum_{j=1}^{K}(\hat{{y}}_{ij} -{y}_{ij})^2 $, which is the mean squared difference between the vector coordinates of the predicted label of the image and the ones of the actual label $\mathbf{y}_i$.
Minimizing the loss over the whole training set is referred to as "training the model". Furthermore, the goal is that given new data we have not seen before and we have not trained our model with, the model will still be able to classify accurately.
Before we go into the details of the model and how we will train it, let's prepare the data.
For our task, we will be using Radial Basis Function (RBF) Networks as our neural network model.
The pipeline, which is presented in the image below, consists of two layers. The first employs non-linear functions $g_1(\mathbf{x};\boldsymbol{\mu}): \mathbb{R}^{n \times d} \rightarrow \mathbb{R}^{n \times c}$.
The second is a linear layer, represented by a matrix of weights $\mathbf{W} \in \mathbb{R}^{c \times K}$, which maps the output of the previous layer to class scores; its role is to predict labels.
The pipeline proceeds in the following steps:
i) Choose a set of $c$ points $\boldsymbol{\mu}_j\in [0,1]^d$.
ii) Compute $g_1(\mathbf{x}_i;\boldsymbol{\mu}_j) = \exp^{-\frac{||{\mathbf{x}_i-\boldsymbol{\mu}_j||^2}}{\sigma^2}}=a_{ij}$ for all possible pairs of $i$ and $j$. Here $\sigma$ is a hyperparameter that controls the width of the gaussian.
iii) Compute the predicted labels $g_2(\mathbf{a}_i)= \mathbf{a}_i^{\top}\mathbf{W}= \hat{\mathbf{y}}_i$. Here $\mathbf{a}_i \in \mathbb{R}^c$ are the outputs of the layer $g_1$ for an input image $i$. $\hat{\mathbf{y}}_i$ is a row vector and $\hat{y}_{ij} = \sum_{m=1}^{c}a_{im}w_{mj}$, $j\in\{1,...,K\}$.
Intuitively, the first layer of the RBF network can be viewed as matching the input data with a set of prototypes (templates) through a gaussian whose width is determined by $\sigma$. The second layer performs a weighted combination of the matching scores of the previous layer to determine the predicted label for a given point.
**1.** For hyperparameters $c$ and $\sigma$ of your choice, select $c$ prototypes and obtain the output of the first layer of the RBF network. The prototypes can simply be random images from your training set.
You can (optionally) perform an additional normalization step on the activations using the [softmax](https://docs.scipy.org/doc/scipy/reference/generated/scipy.special.softmax.html) function.
To make things easier, we will fix the parameters $\boldsymbol{\mu}$ and $\sigma$ of the network, i.e., we decide their values before and the remain constant throughout training and testing of the model. Therefore, the only trainable parameters are going to be the weights of the second layer.
To train the model, we are going to use the mean squared loss function that we mentioned earlier. For a training dataset with $n$ images we have
Backpropagation depends on [gradient descent](https://en.wikipedia.org/wiki/Gradient_descent#Description). The goal is to update the trainable parameters of the network by "moving them" in the direction that will decrease the loss function.
In our case, the weights $w_{kl}$ are updated in the following manner
where $\gamma$ is a hyper-parameter called the learning rate. The gradient of the Loss points towards the direction of steepest descent, hence we update the weights of the network towards that direction.
3. Train the weights of the linear layer using stochastic gradient descent. For $p$ iterations (called epochs), you have to update each weight $w_{kl}$ of the network once for each image, by computing the gradient of the loss with respect to that weight.
NB:if you implement gradient computation naively, it might be very slow. Consider using [numpy.outer](https://numpy.org/doc/stable/reference/generated/numpy.outer.html) to speed up computation.
The system is overdetermined. We have more equations (1 equation per data point) than unknown variables (1 variable for each template). We can find approximate solutions with a [least squares](https://en.wikipedia.org/wiki/Overdetermined_system#Approximate_solutions) approach, i.e., using the pseudoinverse.
Here are a few things that can be tried in order to better select the template images:
- split up the images based on label and sample an equal amount of images from each class. This ensures that there won't be imbalances in the representations of templates/centers.
- split up the images based on label and furthermore subdivide the images of each class into a few groups. Compute the average image in each group. You will have a few "average images" in each class. Use those as centroids/templates. (All of this averaging stuff is easily done with matrix ops)
- filter the images (similar to how it was done in previous notebooks) and then sample extra centers from the filtered data. Use those as additional centers.
- apply standard clustering techniques like [K-Means](https://en.wikipedia.org/wiki/K-means_clustering) and [Spectral Clustering](https://en.wikipedia.org/wiki/Spectral_clustering)

{kind=link}