Add midterm solutions
Showing
- previous-exams/2022-midterm-code/.gitignore 7 additions, 0 deletionsprevious-exams/2022-midterm-code/.gitignore
- previous-exams/2022-midterm-code/.scalafmt.conf 4 additions, 0 deletionsprevious-exams/2022-midterm-code/.scalafmt.conf
- previous-exams/2022-midterm-code/Readme.md 41 additions, 0 deletionsprevious-exams/2022-midterm-code/Readme.md
- previous-exams/2022-midterm-code/bench-results/CollectionBenchmarkResults.json 8260 additions, 0 deletions...idterm-code/bench-results/CollectionBenchmarkResults.json
- previous-exams/2022-midterm-code/bench-results/CollectionBenchmarkResults.txt 33 additions, 0 deletions...midterm-code/bench-results/CollectionBenchmarkResults.txt
- previous-exams/2022-midterm-code/bench-results/CollectionBenchmarkResults_drop.json 4132 additions, 0 deletions...m-code/bench-results/CollectionBenchmarkResults_drop.json
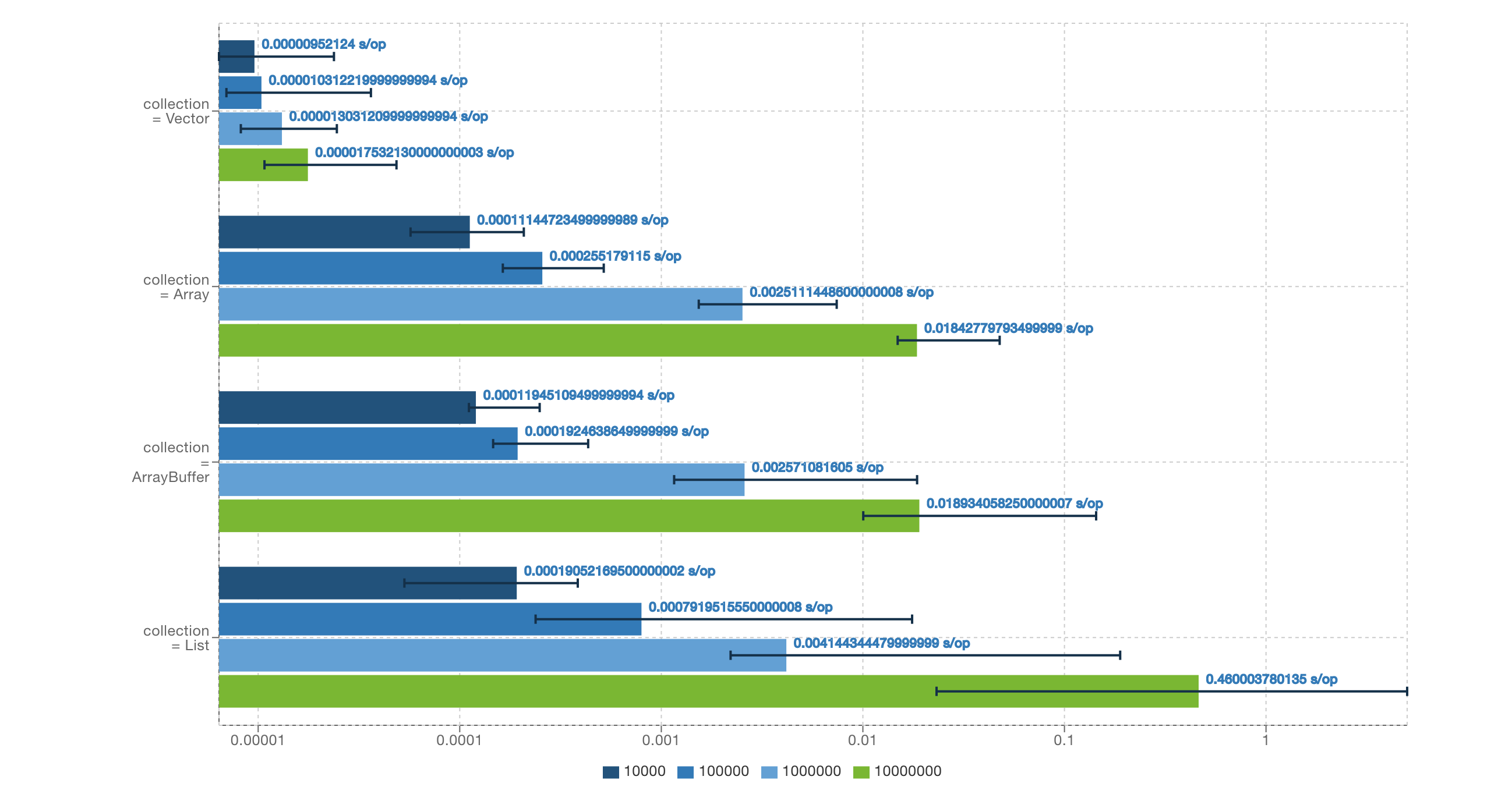
- previous-exams/2022-midterm-code/bench-results/CollectionBenchmarkResults_drop.png 0 additions, 0 deletions...rm-code/bench-results/CollectionBenchmarkResults_drop.png
- previous-exams/2022-midterm-code/bench-results/CollectionBenchmarkResults_take.json 4132 additions, 0 deletions...m-code/bench-results/CollectionBenchmarkResults_take.json
- previous-exams/2022-midterm-code/bench-results/CollectionBenchmarkResults_take.png 0 additions, 0 deletions...rm-code/bench-results/CollectionBenchmarkResults_take.png
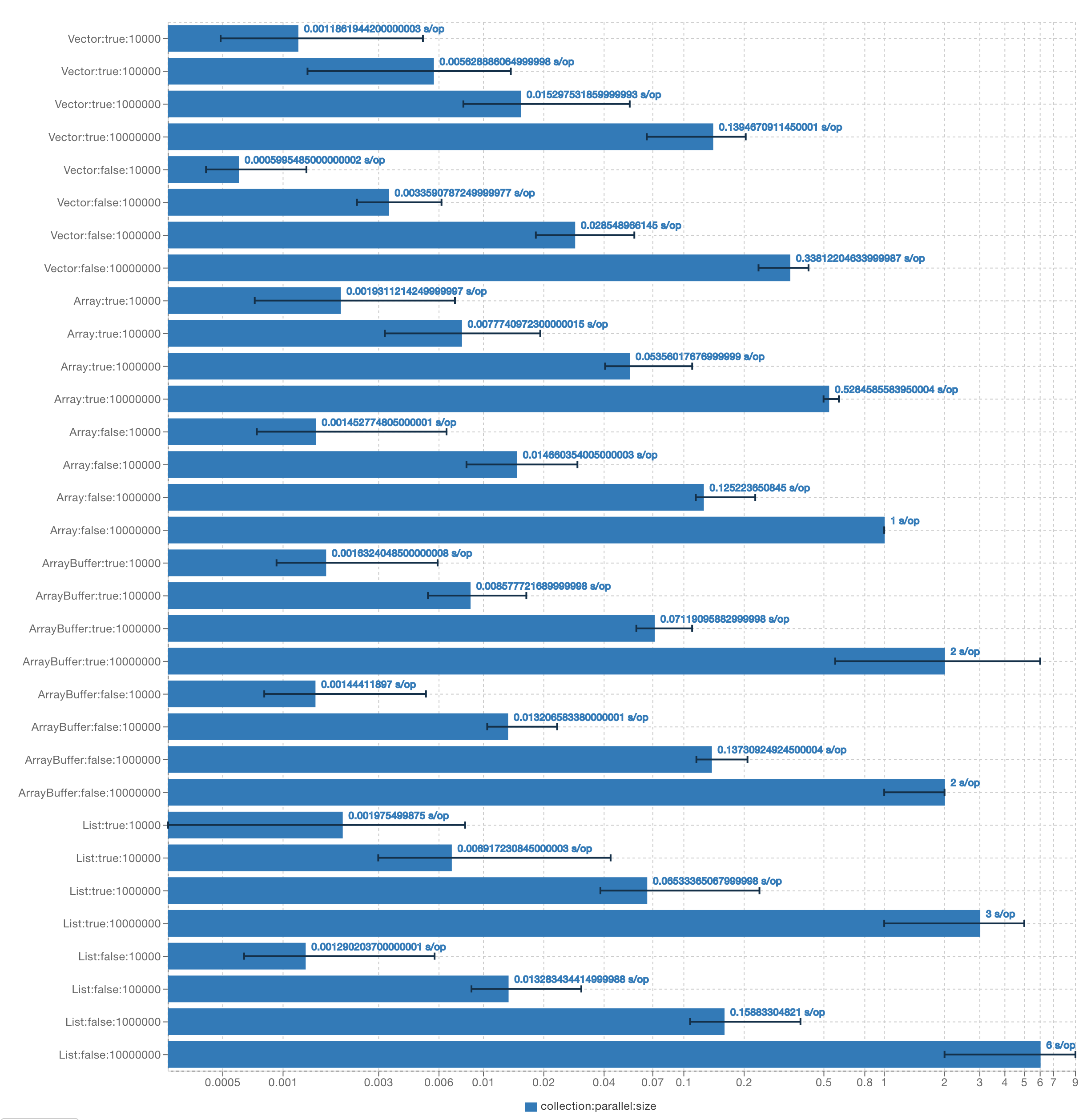
- previous-exams/2022-midterm-code/bench-results/Part2BenchmarkResults.json 8292 additions, 0 deletions...022-midterm-code/bench-results/Part2BenchmarkResults.json
- previous-exams/2022-midterm-code/bench-results/Part2BenchmarkResults.png 0 additions, 0 deletions...2022-midterm-code/bench-results/Part2BenchmarkResults.png
- previous-exams/2022-midterm-code/build.sbt 19 additions, 0 deletionsprevious-exams/2022-midterm-code/build.sbt
- previous-exams/2022-midterm-code/project/plugins.sbt 2 additions, 0 deletionsprevious-exams/2022-midterm-code/project/plugins.sbt
- previous-exams/2022-midterm-code/src/main/scala/bench/AbstractCollectionBenchmark.scala 23 additions, 0 deletions...de/src/main/scala/bench/AbstractCollectionBenchmark.scala
- previous-exams/2022-midterm-code/src/main/scala/bench/CollectionBenchmark.scala 12 additions, 0 deletions...dterm-code/src/main/scala/bench/CollectionBenchmark.scala
- previous-exams/2022-midterm-code/src/main/scala/bench/Part2Benchmark.scala 20 additions, 0 deletions...22-midterm-code/src/main/scala/bench/Part2Benchmark.scala
- previous-exams/2022-midterm-code/src/main/scala/midterm/Mock1.scala 14 additions, 0 deletions...xams/2022-midterm-code/src/main/scala/midterm/Mock1.scala
- previous-exams/2022-midterm-code/src/main/scala/midterm/Mock2.scala 20 additions, 0 deletions...xams/2022-midterm-code/src/main/scala/midterm/Mock2.scala
- previous-exams/2022-midterm-code/src/main/scala/midterm/Part1.scala 45 additions, 0 deletions...xams/2022-midterm-code/src/main/scala/midterm/Part1.scala
- previous-exams/2022-midterm-code/src/main/scala/midterm/Part2.scala 45 additions, 0 deletions...xams/2022-midterm-code/src/main/scala/midterm/Part2.scala
previous-exams/2022-midterm-code/.gitignore
0 → 100644
previous-exams/2022-midterm-code/Readme.md
0 → 100644
This diff is collapsed.
This diff is collapsed.
{kind=link}
204 KiB
This diff is collapsed.
{kind=link}

235 KiB
This diff is collapsed.
{kind=link}
546 KiB
previous-exams/2022-midterm-code/build.sbt
0 → 100644