
Initial commit
parents
No related branches found
No related tags found
Showing
- .gitignore 9 additions, 0 deletions.gitignore
- figures/10-cliques-validation-accuracy.pdf 0 additions, 0 deletionsfigures/10-cliques-validation-accuracy.pdf
- figures/d-cliques-cifar10-vs-1-node-training-loss.png 0 additions, 0 deletionsfigures/d-cliques-cifar10-vs-1-node-training-loss.png
- figures/d-cliques-cifar10-vs-1-node-validation-accuracy.png 0 additions, 0 deletionsfigures/d-cliques-cifar10-vs-1-node-validation-accuracy.png
- figures/figures.key 0 additions, 0 deletionsfigures/figures.key
- figures/fully-connected-IID-vs-non-IID.png 0 additions, 0 deletionsfigures/fully-connected-IID-vs-non-IID.png
- figures/fully-connected-cliques.pdf 0 additions, 0 deletionsfigures/fully-connected-cliques.pdf
- figures/grid-IID-vs-non-IID.png 0 additions, 0 deletionsfigures/grid-IID-vs-non-IID.png
- figures/grid-iid-neighbourhood.png 0 additions, 0 deletionsfigures/grid-iid-neighbourhood.png
- figures/grid-non-iid-neighbourhood.png 0 additions, 0 deletionsfigures/grid-non-iid-neighbourhood.png
- figures/ring-IID-vs-non-IID.png 0 additions, 0 deletionsfigures/ring-IID-vs-non-IID.png
- llncs.cls 1218 additions, 0 deletionsllncs.cls
- main.bib 666 additions, 0 deletionsmain.bib
- main.tex 293 additions, 0 deletionsmain.tex
- splncs04.bst 1548 additions, 0 deletionssplncs04.bst
.gitignore
0 → 100644
figures/10-cliques-validation-accuracy.pdf
0 → 100644
File added
{kind=link}
141 KiB
{kind=link}
89.9 KiB
figures/figures.key
0 → 100755
File added
figures/fully-connected-IID-vs-non-IID.png
0 → 100644
{kind=link}
54.7 KiB
figures/fully-connected-cliques.pdf
0 → 100644
File added
figures/grid-IID-vs-non-IID.png
0 → 100644
{kind=link}
115 KiB
figures/grid-iid-neighbourhood.png
0 → 100644
{kind=link}
18.7 KiB
figures/grid-non-iid-neighbourhood.png
0 → 100644
{kind=link}
14.2 KiB
figures/ring-IID-vs-non-IID.png
0 → 100644
{kind=link}
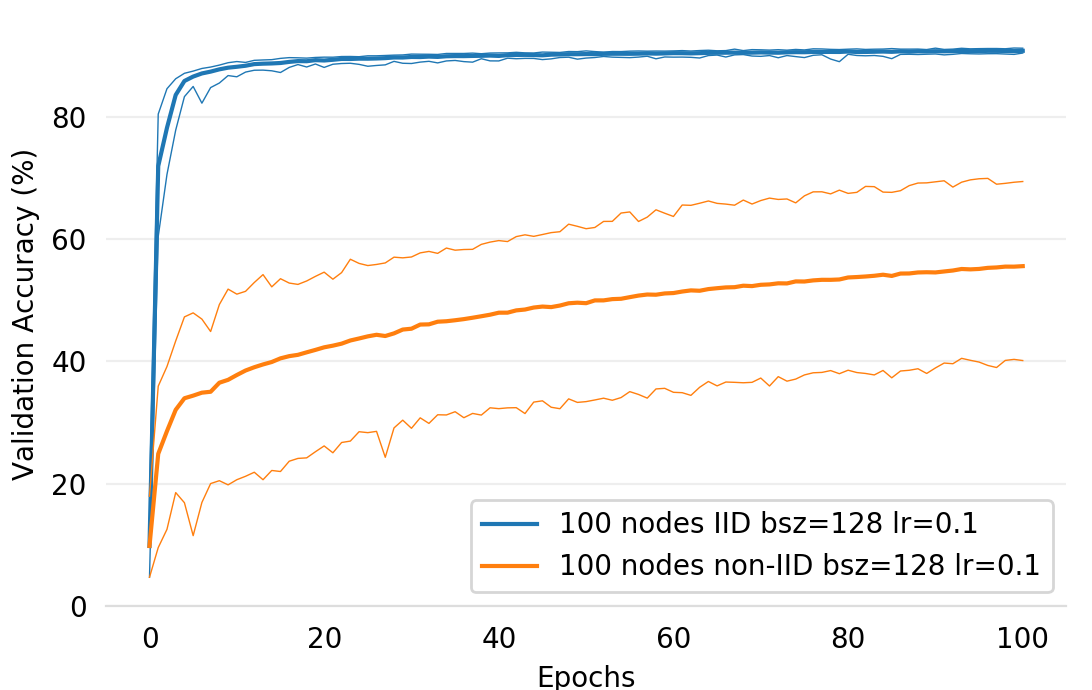
86.5 KiB
llncs.cls
0 → 100644
main.bib
0 → 100644
main.tex
0 → 100644
splncs04.bst
0 → 100644